Abstract
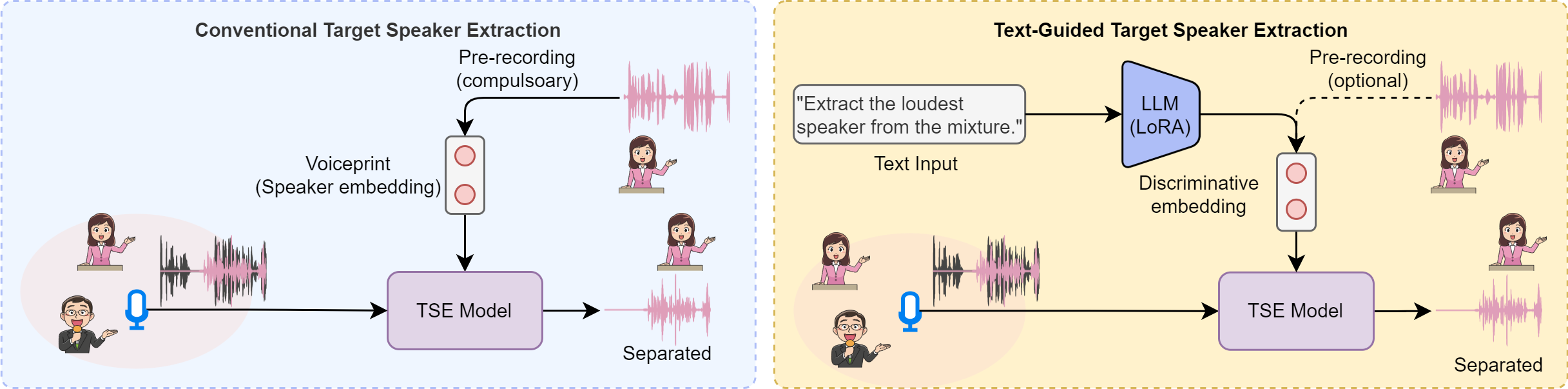
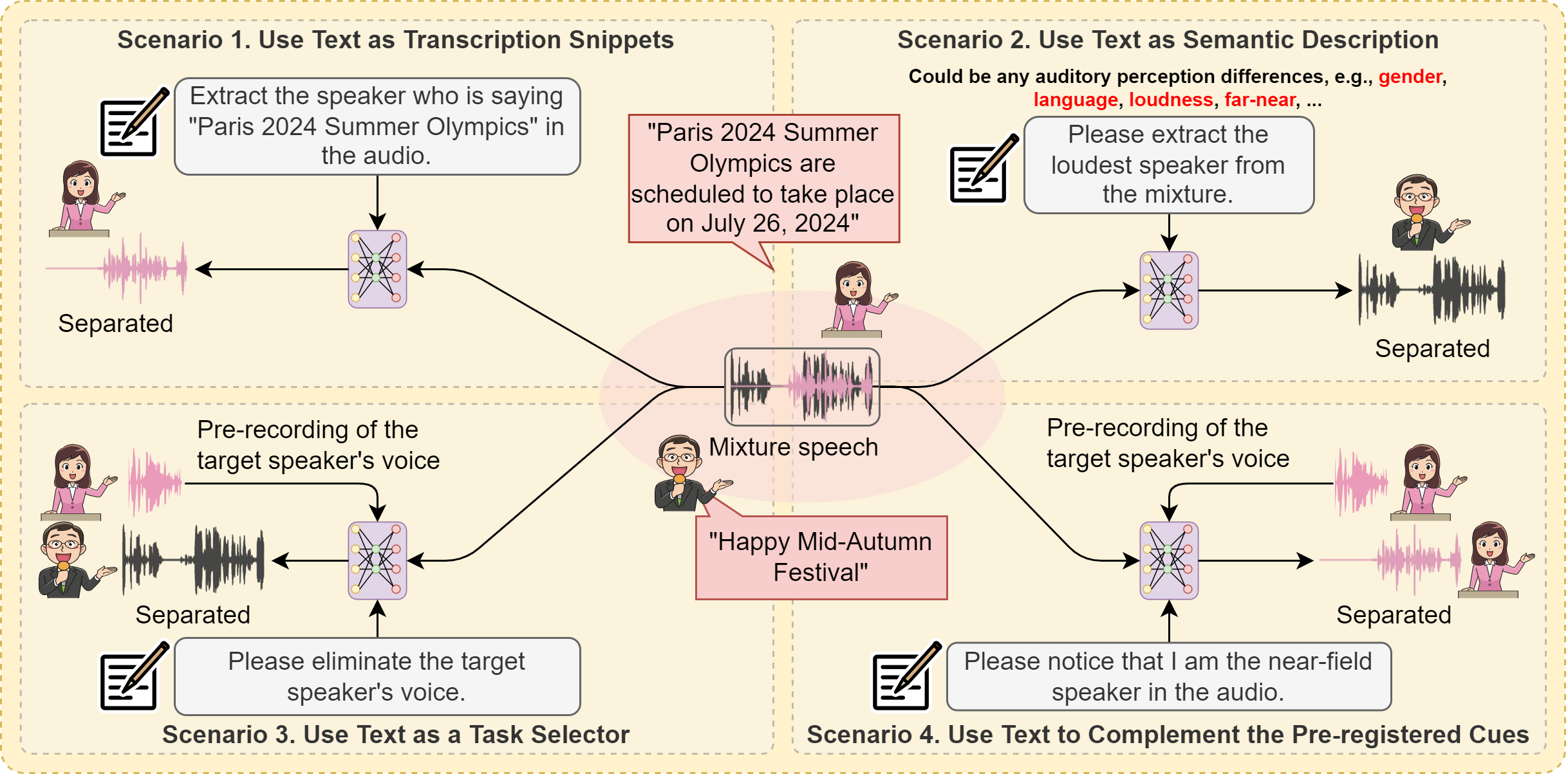
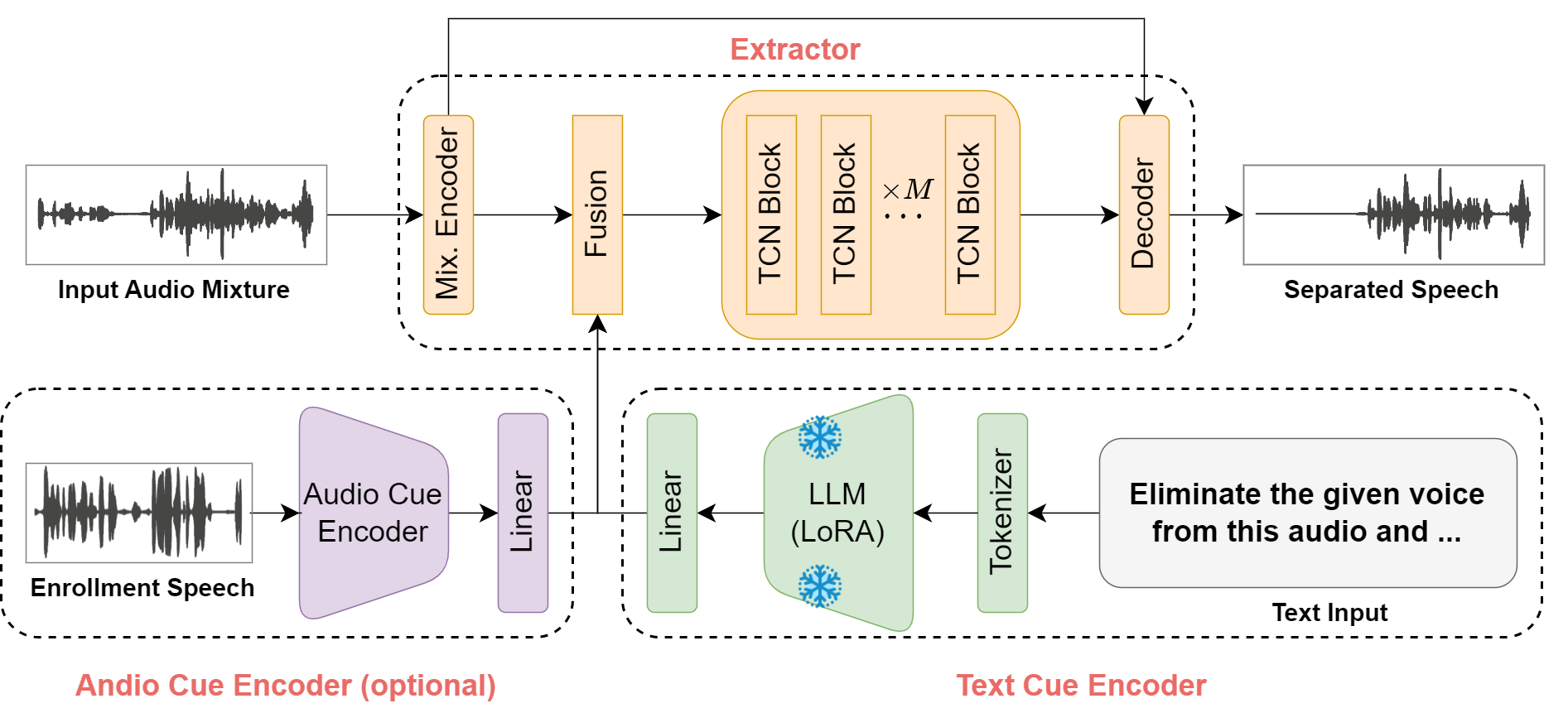
Humans possess an extraordinary ability to selectively focus on the sound source of interest amidst complex acoustic environments, commonly referred to as cocktail party scenarios. In an attempt to replicate this remarkable auditory attention capability in machines, target speaker extraction (TSE) models have been developed. These models leverage the pre-registered cues of the target speaker to extract the sound source of interest. However, the effectiveness of these models is hindered in real-world scenarios due to the unreliable or even absence of pre-registered cues. To address this limitation, this study investigates the integration of natural language description to enhance the feasibility, controllability, and performance of existing TSE models. Specifically, we propose a model named LLM-TSE, wherein a large language model (LLM) extracts useful semantic cues from the user's typed text input. These cues can serve as independent extraction cues, task selectors to control the TSE process or complement the pre-registered cues. Our experimental results demonstrate competitive performance when only text-based cues are presented, the effectiveness of using input text as a task selector, and a new state-of-the-art when combining text-based cues with pre-registered cues. To our knowledge, this is the first study to successfully incorporate LLMs to guide target speaker extraction, which can be a cornerstone for cocktail party problem research.
Preview
Preview
Preview
Demo
Transcription Snippets
| Mixture | Enrollment (Audio) | Enrollment (Text) | Separated |
|---|---|---|---|
| w/o | Extract the speaker who is saying 'the mixture the affected parts' from this audio? | ||
| w/o | |||
| Please note that the person speaking 'the mixture the affected parts' in the mixed audio should be extracted. | |||
| I don't want to the given voice of in this audio. | |||
| w/o | I need 'it was plain that only the ponies could go by it' spotted from this audio. | ||
| w/o | |||
| Please extract 'it was plain that only the ponies could go by it' in the mixed audio. | |||
| Is it possible to erase the given voice from this audio? |
Loudness or Far/Near
| Mixture | Enrollment (Audio) | Enrollment (Text) | Separated |
|---|---|---|---|
| w/o | Help me extract the speech signal of the loudest speaker. | ||
| w/o | |||
| Notice that the loudest sound in the mixed audio should be extracted. | |||
| Remove the given voice from the mixtrue. | |||
| w/o | Help me retrieve the speech signal corresponding to far away from the microphone. | ||
| w/o | |||
| The speaker is far away from the microphone, and the reverberat is very serious. | |||
| Eliminate the registered voice from this audio. |
Gender
| Mixture | Enrollment (Audio) | Enrollment (Text) | Separated |
|---|---|---|---|
| w/o | Could you support me in identifying and extracting the voice of male from this audio? | ||
| w/o | |||
| The male voice in the mixed audio should be extracted. | |||
| Can you remove the specified voice from this audio? | |||
| w/o | Can you extract the specific voice of male from this audio? | ||
| w/o | |||
| The extracted speaker should be a man. | |||
| Please remove the specified voice from this audio. |
Language
| Mixture | Enrollment (Audio) | Enrollment (Text) | Separated |
|---|---|---|---|
| w/o | Is it possible to isolate the Spanish voice in this speech mix? | ||
| w/o | |||
| Please extract the Spanish voice in the mixed audio. | |||
| Eliminate the given voice from this audio. | |||
| w/o | Would you be able to assist me in isolating the English voice from this mixture speech? | ||
| w/o | |||
| Please extract the English voice in the mixed audio. | |||
| Please remove the specified voice from this audio. |